Senthil PalanisamySensing and understanding the outside world through sensors is a fascinating process that opens your mind to the beauty of mathematics, research, programming and engineering
I am Senthil Palanisamy. I was born and brought up in India. I moved to US in August 2019 to begin my Masters in Robotics at Northwestern. My undergraduation was in electronics and then I worked for about 3 years in computer vision. Right now, I get excited about solving robotics problems involving computer vision.
Education
Bachelor of Engineering in Electronics & Communication - Anna University (Graduated May 2016.)
Master of Science in Robotics - Northwestern University (Graduated in Dec 2020)
Experience: 5 Years
Geomagical labs | Applied Research Engineer (August 2021 - Present)
TartanSense | Robotics Engineer - (March - July 2019)
Soliton Technologies | Computer Vision R&D Engineer(May 2016- Feb 2019)
For more information about this experience please see my resume (button below).
Courses taken
The courses I have taken include: Embedded Systems, Robotic Manipulation, Machine Dynamics, ML and AI for robotics
The online courses I have completed include Stanford CS231n- Convolutional Neural Networks for Visual Recognition, Stanford CS229- Machine Learning, MIT 18.06- Linear Algebra, MIT 6.041 - Probabilistic Systems Aand Applied Probability, MIT 6.006 - Introduction to Algorithms
From Jaisimha Rao, Founder/ CEO of TartanSense ( I worked in TartanSense for 4 months )
Senthil joined TartanSense at the product development stage where he displayed a set of skills that is rare amongst Robotics Engineers.
Senthil's "superpower" is his ability to cut through all the noise and make thorough decisions with clarity. This is indeed a gift for any organization that has several stakeholders with strong opinions. Senthil's performance in such a setting where his, firm but polite manner of communicating technical decisions made him shine in several crucial product development conversations.
Senthil subsequently backed up his decisions by building our data collection robot and our computer vision parameters. Once again his detail-oriented approach of calibrating the camera and working through all combinations helped us avoid any costly delays.
In short, Senthil's strong technical fundamentals combined with his brisk and cheerful demeanor in being a team leader are a set of combined skills that make him valuable to any organization.
From Sumod Mohan, Founder Autoinfer, 10+ years experience in Computer Vision ( I worked under Sumod for 2.7 years)
Senthil was part of the CVD Group at Soliton and made significant contributions in Algorithm Development, Prototype Development, and Product Development for various projects involving Computer Vision Problems such as Object Detection/Recognition, Segmentation and certain Geometric Algorithms. He stood out in his desire to understand problems at its core, to make significant deep technical contributions with their solutions and his discipline to cement his knowledge (as evidenced by the online courses he completed). I am sure he would excel at Research and/or Development in both Academia and Industry.
He is extremely open and promotes openness and that made it very easy to work with him. His enthusiasm for ultra marathons and his desire to make an impact on society also was very apparent and also energized a lot of other Solitons.
Endorsements quoted from Linkedin without modifications. Link to Sumod's Profile.
The primary motivation with this work is to replicate some of the simulation research work carried out in Prof. Malcolm's Maclver's neuroscience lab on actual animals. The lab has primarily been working on predator prey experiments in simulation and published results on the same. In order to verify that some of these results carry over to the results on actual animal, a maze space was setup and a mice is allowed to run inside the maze where it tries to reach a goal position while a robot acts a predator and threatens the mice. In order to make these things a reality, a high speed mice tracking system at more than 100 fps at least is needed since the robot needs to plan online to take up the predator role. Since the total area is about 200 cm x 200 cm, the pixel / mm required for imaging the mice satisfactorily demands the need of using multiple cameras and therefore, a need to do multiview image stitching to stitch the image from camera view naturally emerged.
Hardware Setup
The hardware setup consists of 4 Basler Ace cameras powered by PoCL cables and connected to the computer systems through PCIe framegrabbers. The camera are mounted on above the maze at an approximate height of about 90 cms above the ground using 80/20 frames. The cameras are mounted on the 80 / 20 frames using mounting adapters and T-slots. The system also has a GTX 1050 Ti GPU card for running CUDA enabled computer vision algorithms and deep learning algorithms. The cameras are capable of running at max fps of 187 while the frame grabbers can support their max speed with a highest speed of 400 fps. All of camera parameters were tuned for high speed image capture. In particular, binning was used to utilize the max speed but the downside is that each camera's resolution reduced to 1024 x 1024 from their original 2048 x 2048 resolution. But this was okay and necessary for our application. The cameras run in free-running mode since at such high speed captures, synchronization between cameras wasn't a big concern
Image Stitching
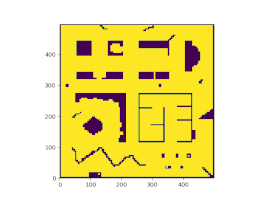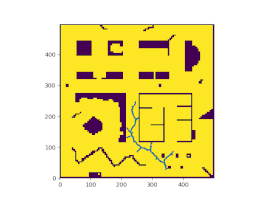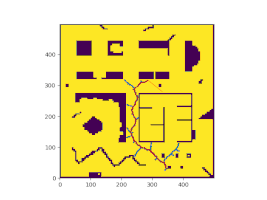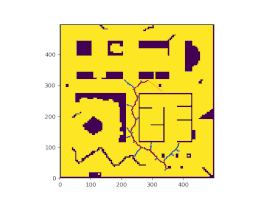
The homography of each camera to the ground plane was determined by using a charuco board and this predetermined homographies were used to stitch the images from 4 camera views together. To keep the post short, all details related to the image stitching is not discussed here. To know in depth details about it please visit my daily medium blog post The stitched image obtained from the pipeline is shown below.
High speed mice tracking
To accomplish high speed mice tracking, I tried out a few strategies namely Object tracking and Background Subtraction. Since mice and robot are the only moving objects in the camera view, these two objects can be identified through background subtraction. The robot is placed with a tag and hence, its position is identified and any dynamic movement corresponding to the robot can be disassociated by locating the position of the tag and the position of the mice can be found by background subtraction. Each cell present in the image is manually labeled and this gives a mechanism for associated the mice position with a cell and this result is superimposed on the stitched image.
For doing more useful offline analysis, I trained a model for tracking the pose of the mice using deeplabcut. This model is obtained by taking the pre-trained deepercut model trained on human pose estimation task and doing a transfer learning with mice data obtained from real experiments. This model is a useful offline tool for analyzing mice behavior. In the video we can see that three mice body parts are tracked cleanly.
The model training and inference code is in python and the whole pipeline is in C++ and therefore to facilitate their integration, I also wrote a interface script based on pybind11 that can run the deeplabcut inference code through the python interpretor in C++
Parallelism in the overall architecture
The whole architecture was heavily parallelized so that the experiments can be conducted online while at the same time logging videos for future reference. In general following were the requirements from the pipeline
Online mice tracking at very high fps (> 100)
Ability to log raw videos for future analysis
Ability to stitch videos and log the stitched video for future analysis
In order accomplish this, the code was heavily multi-threading, thereby utilizing all the cores in the system. std::asyc function in C++ was the primary mechanism used for parallelism. The pipeline has around 13 asynchronous threads that run all the time. The description of each thread is given below
The main action (mice tracking using background subtraction) happens on the main thread at a very high speed
4 slower threads write all the raw acquired images to a video
1 thread constructs a stitched image from the 4 cameras
2-3 sub-threads are utilized by the image stitching thread for transferring pixels
Another 4 threads track the robot position
Hence, in total, around 13 asynchronous threads run in parallel. The following two images show the CPU utilization.
The system has 4 cores with intel's 2 hyperthreads per core, there is a total of 8 virtual cores. It can be seen from the images that all the cores are fully utilized and that the back_ground_subt process takes around 7 cores while one core is utilized by system process. Since more than 13 threads run in these 7 virtual cores on average, the overall application slows down a little but the lab is planning to shift towards a more powerful processor thereby utilizing the parallelism fully. The final speeds achieved for various tasks within the system are shown below
Image capture and mice tracking using background subtraction at more than 100 fps
Raw Video writing at around 30 fps
Stitched image writing at around 10 fps
The code for this project can be found at my github repo
A C++ project for a wheeled robot navigation and SLAM using a EKF filter was constructed from scratch and tested on a turtlebot.
Detailed Explanation
Kinematics for a wheeled robot navigation invloves estimating a robot's movement based control inputs applied. Here, a velocity control was used and the odometric state of the robot was estimated. However, a feedback control gives better results than a feed forward control and hence, the use of wheel encoders improves the accuracy in the robot state estimation. However, our modelling capacity is so limited that this is not useful for long term state estimation. Particulary, factors like wheel slip cannot be modelled through our simple model and the use of SLAM is the reliable solution for long term robot pose and map estimation. SLAM stands for Simultaneous Localisation and Mapping, which means that the robot builds a map and localises itself at the same time. While this is a Chicken and egg problem, several framework do exist for solving this problem reliably. One of the well established techniques for doing this is the use of Kalman filters. In this work, I implemented an Extended Kalman Filter. In short, an extended kalman filter uses a Taylor's series approximation for linearising the motion model and measurement model to preserve the gaussin posterior, an essential requirement for a Kalman Filter. It must be noted here, that choice of EKF SLAM was solely based on the problem requirement- for robot localisation in an environment with no / limited prior knowledge. Hence, a dense map is not genereated through this method. Infact, we get only a few landmarks points that are tracked throughout for state estimation.
Work in Progress
SLAM with known data association has been implemented and verified successfully verified under a gazebo simulation. Ground Truth for Landmarks were taken from the simulation. SLAM under an unknown environment with an unknown data association is a work in progress
Getting a robot to learn based on its interactions with environment is one of the most powerful ideas of all. Mostly of our object manipulation revolves around the rigid body assumption. But in this project, I implemented a work that enables the robot to learn to tie a knot purely based on interacting with its environment. This a self supervised deep learning technique applied to the reinforcement learning problem of learning an effective policy. This work was based on the work on zero shot visual imitation by researchers from UC, Berkley.
Problem Setup
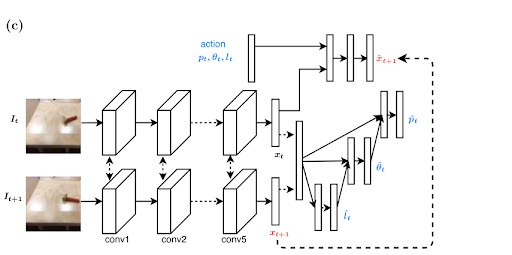
The most fundamental aspect of solving this problem can be formulated as a pick and place action. A complex action such a tying a knot can be decomposed by a few such pick and place actions. Such an action is parameterized by four quantities-The action position in pixel space (x, y), the angle of the action (theta) in the world space and the length of the action in the world space. Thus the objective in this problem is to to learn a policy \(\pi(I_1, I_2)\), where \(\pi\) is a function that predicts the actions that transforms the present state (Image \(I_1\)) to a goal state (Image \(I_2\)). This problem is formulated as a deep learning classification problem that predicts a class label for each action based on the input image and a goal image. It must be noted that the choice of a classification network instead of regression means that we are discretizing the output actions. For predicting continuous actions, a regression network is more ideal but the choice of classification network makes this learning feasible, which didn't seem to converge with a regression network. The network used in the work is shown below
The above network minimizes two objectives- The forward loss and the inverse loss. The forward function predicts the next state given the present state and an action to be applied while the inverse function predicts the action that transforms the present state to a goal state (The present state and the goal state are represented through images). This network is built from a Alexnet base - the first 5 convolutional layer structures and the initialisation of weights for these layers are taken from the Alexnet architectures while the fully connected layers are are modified to fit the specific problem. While this network can predict small actions between nearby states, it cannot predict the sequences of actions that leads to tying a knot for example. To accomplish a complex task, a demo is first given to the machine and the complex action is thus decomposed into a sequence of images, where every pair of images is not too far away in terms of states. The system can then predict the action that leads to every sequential image in the demo that was shown thereby predicting a sequence of actions that accomplishing the complex know tying task.
But action predictions are not always correct. Sometimes wrong actions are predicted and hence, to handle such wrong predictions, a goal recogniser network is constructed. The goal recognizer is a simple binary classification network, that given two images, predicts if both of them belong to the same state. This network is constructed with the same Alexnet base but with only one neuron at the final fully connected layer. Thus this network is used after every applied action to check if the state has reached the next intermediate goal state in the sequence and the intermediate goal state is switched to the next intermediate goal if the network output is positive.
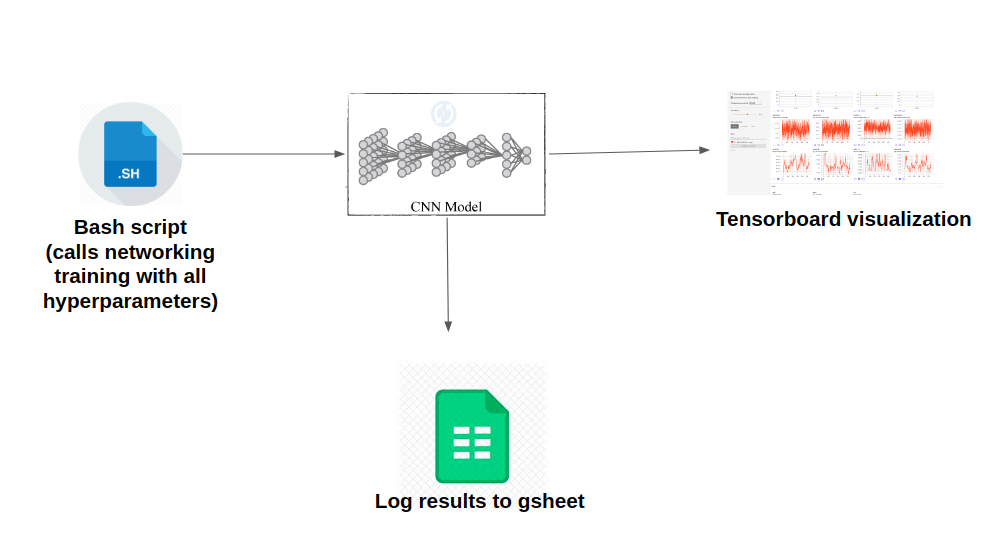
Automation and Debugging tools
One of the most important things when trying to train neural networks is to automate as much as possible so that a lot of experiments could be run for tuning the parameters. Another important aspect is to build visualization tools that will greatly aid in network debugging. Without these tools, it will be a nightmare to debug neural network when something goes wrong. The figure below shows the pipeline I used to minimise manual work so that I could run a lot fo experiments with very minimal work. A bash script contains a lot of scheduled experiments along with their hyper parameters. This script calls the training code, which after training for a predefined number of epochs logs results to an online gsheet. The program also logs results and debugging data into a directory, which can be visualized using tensor board.
The following figure shows some of the visualization tools that were integrated to help debug the model construction and training process.
Training results and visualisation
Training the model in one shot is difficult and makes it difficult to converge. In order to facilitate the training process, first the network is trained with the inverse objective alone and then the converged network is trained again with the joint objective of both the forward and inverse loss. Among 100s of experiments a sample of few best results are shown below.
It must be noted here that the accuracy metric used here is not a very accurate measure for the task at hand since multiple actions could lead to the same state. Nevertheless, this serves as a proof that the model has learned something useful.A visualization of the model's prediction is given below, where the yellow arrow indicates that action (the x,y pixel location to pick, the angle at which to pick up and the distance to move in the direction) so that the state can be changed from the given state (image at the top) to a goal image(image at the bottom)
It must be noted that these are a few cherry picked results and there exists a lot of bad results as shown below
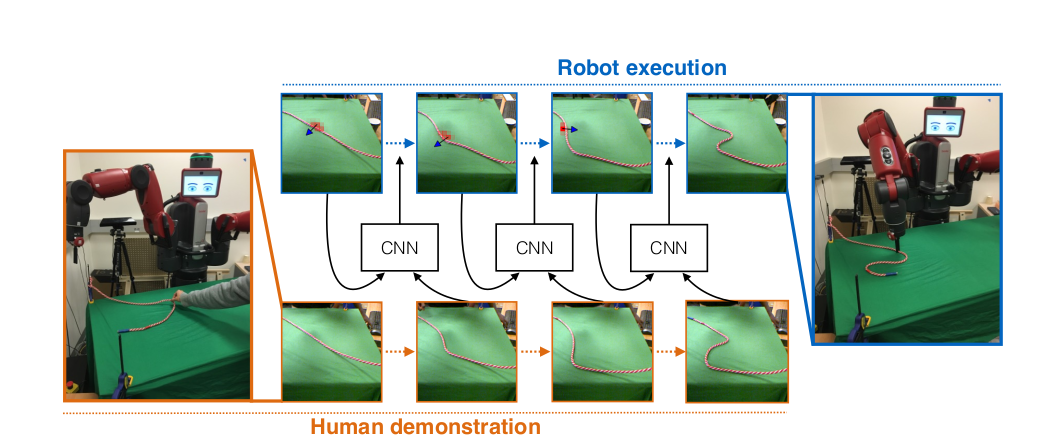
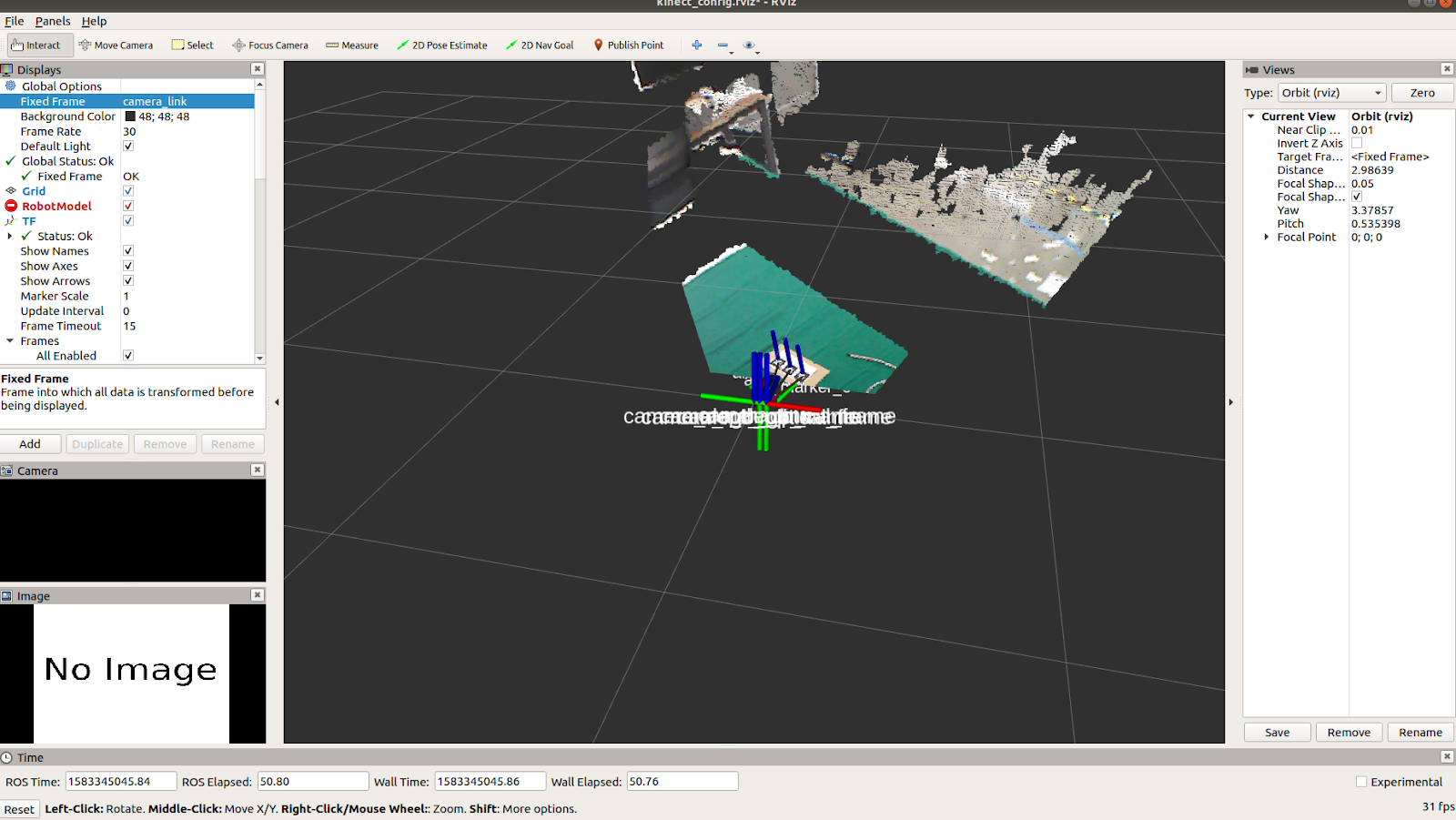
Hardware Implementation(In progress)
A kinect camera is used so that the depth corresponding to any x,y pixel location can be directly obtained. First the relative transformation between baxter and kinect is calculated using a AR tag that is visible in both the kinect camera and baxter's camera as shown below.
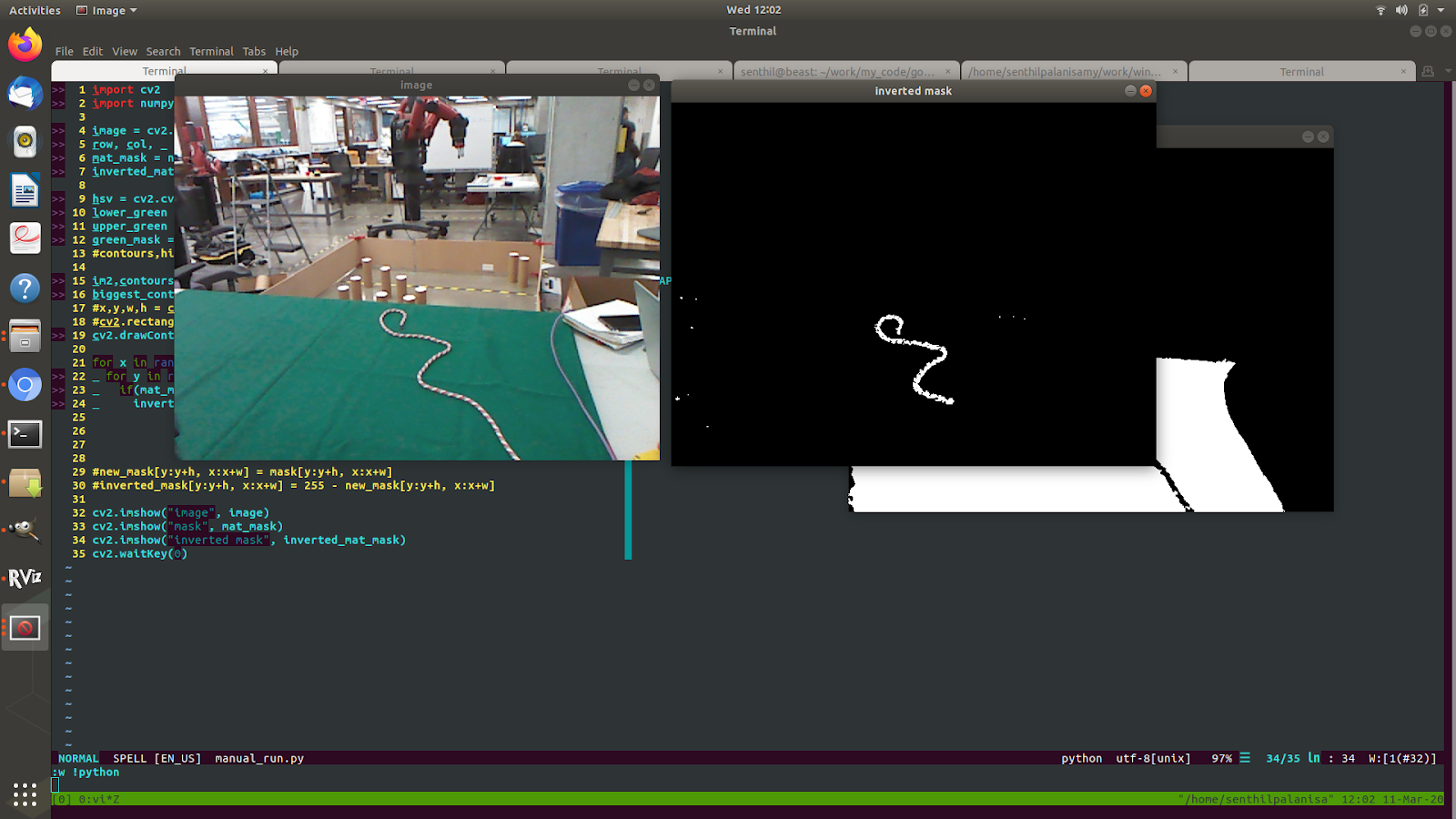
Next a simple computer vision code was written using masking and connected component analysis to find the rope. Though the network's prediction directly gives out the pixel locations to execute the action, this step is done so that the action can be slightly adjustment if a prediction is given in a pixel location very close to rope but outside the rope.
The code for this project can be found at this github repo. Practical tips for debugging neural networks can be found in this blog
I read 51 papers in the area of visual SLAM and summarized my understanding into a short survey paper
Detailed Overview
The goal of this survey is to gain a broad knowledge on the techniques of SLAM and to gain an insight into the evolving role of vision in present day SLAM. The primary objective is not to be coarse and learn these systems at a block diagram level but to dig deeper and understand them at the mathematical formulation level. Visual SLAM is a huge community. With the introduction of new sensors, the role of vision in SLAM is actively getting redefined. The paper selection methodology is such that papers are sampled across all sensing modalities that can be used in combination with a vision system. Attention was also paid to distribute papers across different SLAM frameworks and visual SLAM techniques. Thus at the end of this paper, it is my primary objective to be well versed in all of the vocabulary used across all of visual SLAM system and to summarize my understanding and inference in a clean way for future reference.
Paper and Presentation
To get a concise view of ideas presented in the survey, please refer to presentation. For a more detailed view of all ideas presented, please download my report
I implemented the whole node for computer vision, which detects AR blocks, red lego blocks and does inverse projection to find the 3D location of a point on a known plane corresponding to a pixel on the camera. I also setup the RoS pipeline for the whole project and integrated my node into our RoS pipeline
Overview
For this project, Baxter assembles a MEGA BLOKS pyramid from the blocks provided by the user. The flow is:
The Blocks that can be picked up are detected on Baxter's camera image using OpenCV
Among all detected blocks, a block is chosen at random and its 3D location is estimated
The block is picked up and moved to the drop location using position control in Moveit
The block is pressed against the plate by using force control in Moveit and finally, as a double check, the gripper hand is pushed against the block to ensure that the block is pushed in.
detailed explanation
computer vision
We used the Baxter's right hand to observe the base plate, spot a red brick and determine its position for pickup. First to know the plane in which the base plate is located, all AR frames visible in the camera's field of view are detected. Then the pre-calibrated intrinsic camera parameters are used to find inverse projection ray corresponding to a pixel on the camera's sensor. Then the 3D location corresponding to a pixel is calculated by finding the intersection of the inverse projected ray and ground plane defined by one of AR tags. The 3D point corresponding to the pixel is determined in multiple AR frames and then these points are converted to the Baxter world frame representation. As a result, we get multiple points in world frame that correspond to the same pixel in Baxter's camera image but obtained using different AR frames as reference. The median of all those points is found out and that point is taken to be the true 3D location corresponding to the pixel in the image. Reason why we use multiple AR frames when one should be sufficient in theory - Sometimes AR tags are affected by lighting and their 3D pose with respect to the camera oscillates. Even worse sometimes, they are not detected. Using multiple AR tags this way increases both the roboustness and the precision of the system. We were able to locate points within +/- 1 cm accuracy through this process.
Pickup and Placning
We then use move it to move Baxter's left arm to the block pickup location, pickup the block by controlling gripper through Baxter's native libraries and then use move it again to move the blocks to a pre-configured goal location. Position control was used to move Baxter's arm to pickup and drop locations. We had standoff points before the pickup and drop, that were designed to be a few cms above the actual pickup and drop location. When placing the block, we used force control to press the block against the plate. The whole process is repeated until 3 blocks are placed to construct a small pyramid. A video showing this whole process in action is shown below but it should be noted that the video has been sped up 3x for viewing convenience
If you want to know more on the project, please check out the code in github.
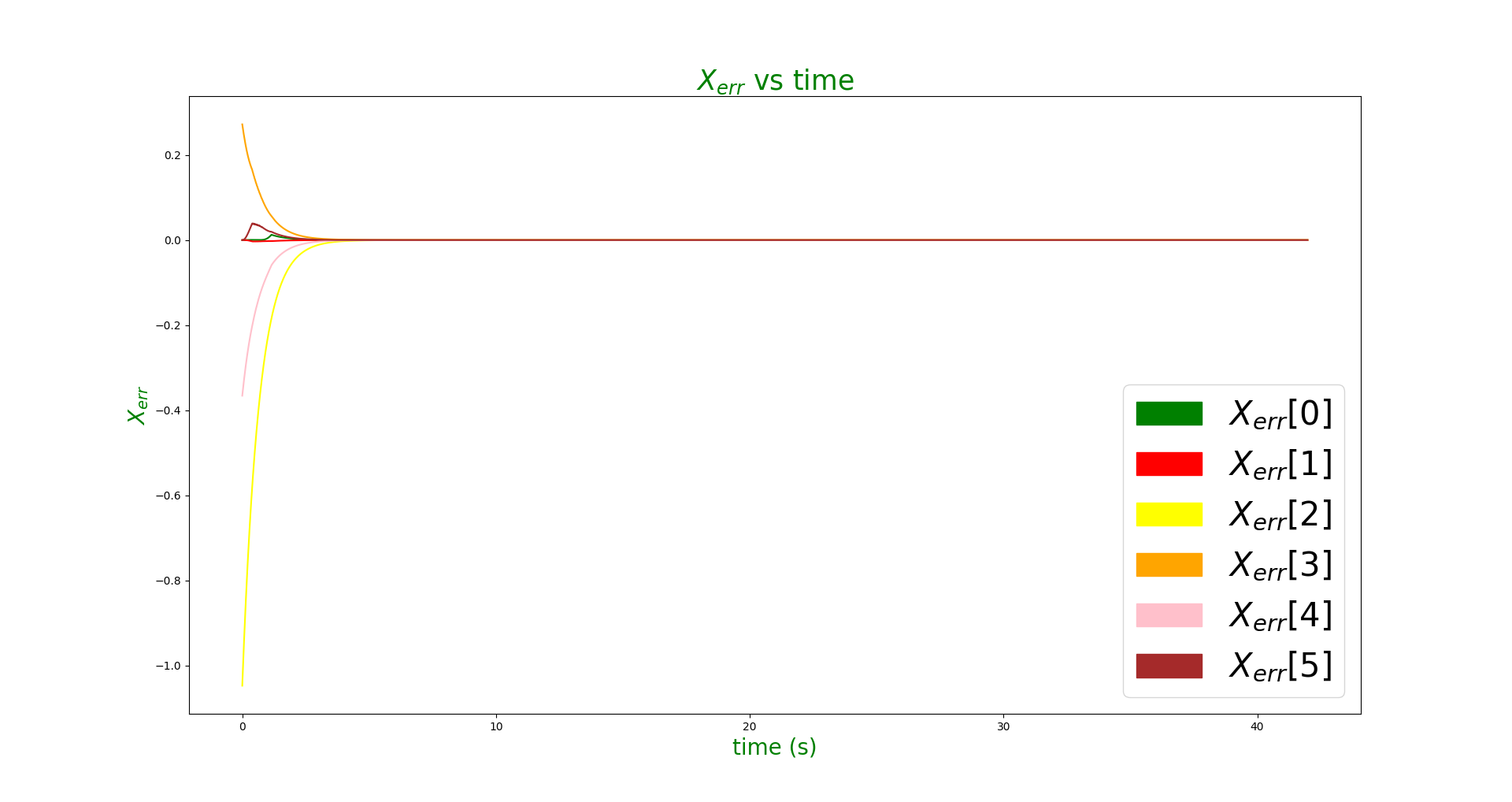
As the final project for the course on Robotic Manipulation, I implemented a PI feedforward controller for a 4 wheeled mobile robot with a 5 dof arm for an object manipulation task. The arm has 5 degrees of freedom and the wheels add 4 degrees of freedom making this a redundant robot with 9 degrees of freedom. The PI feed forward controller contains three terms $$ V(t) = [Ad_{X^{-1}X_d}] V_d(t) + K_{p} X_{err}(t) + K_{i} \int_{0}^{t} X_{err}(t) dt.$$
The feed forward term \([Ad_{X^{-1}X_d}] V_d(t)\) which generates the twist for following a desired trajectory. (V_d is the twist required to take current desired end effector configuration to the next desired end effector configuration and is given by \([V_d] = (1 / \Delta t) log(X_d^{-1} X_{d, next})\) . This twist is then converted from the current desired end endeffector frame to the actual current end effector frame
An error term which react to the error of the end effector \(K_{p} X_{err}(t)\) (the twist required to take the current end effector configuration to a desired end effector configuration at the current time step)
An integral term which keeps a running sum of the errors accumulated so far.\(K_{i} \int_{0}^{t} X_{err}(t) dt\) ( summation of the error twists over time )
The output twist obtained by summing all three terms is then converted to robot velocity commands by using the Jacobian matrix associated with the 9D robot. \(\begin{pmatrix} u \\ \dot{\theta} \end{pmatrix} = J_e^{+} V.\)
Then the robot configuration is estimated by the applying the command velocities through the kinematic model of youbot.
A few observations
The kerms Kp and Ki control how the system behaves
A high value of Kp brings down the errors rapidly width="400".
A low value of Kp just makes the system’s response to errors slower.
But a very high value of Kp causes jerky motion in the robot.
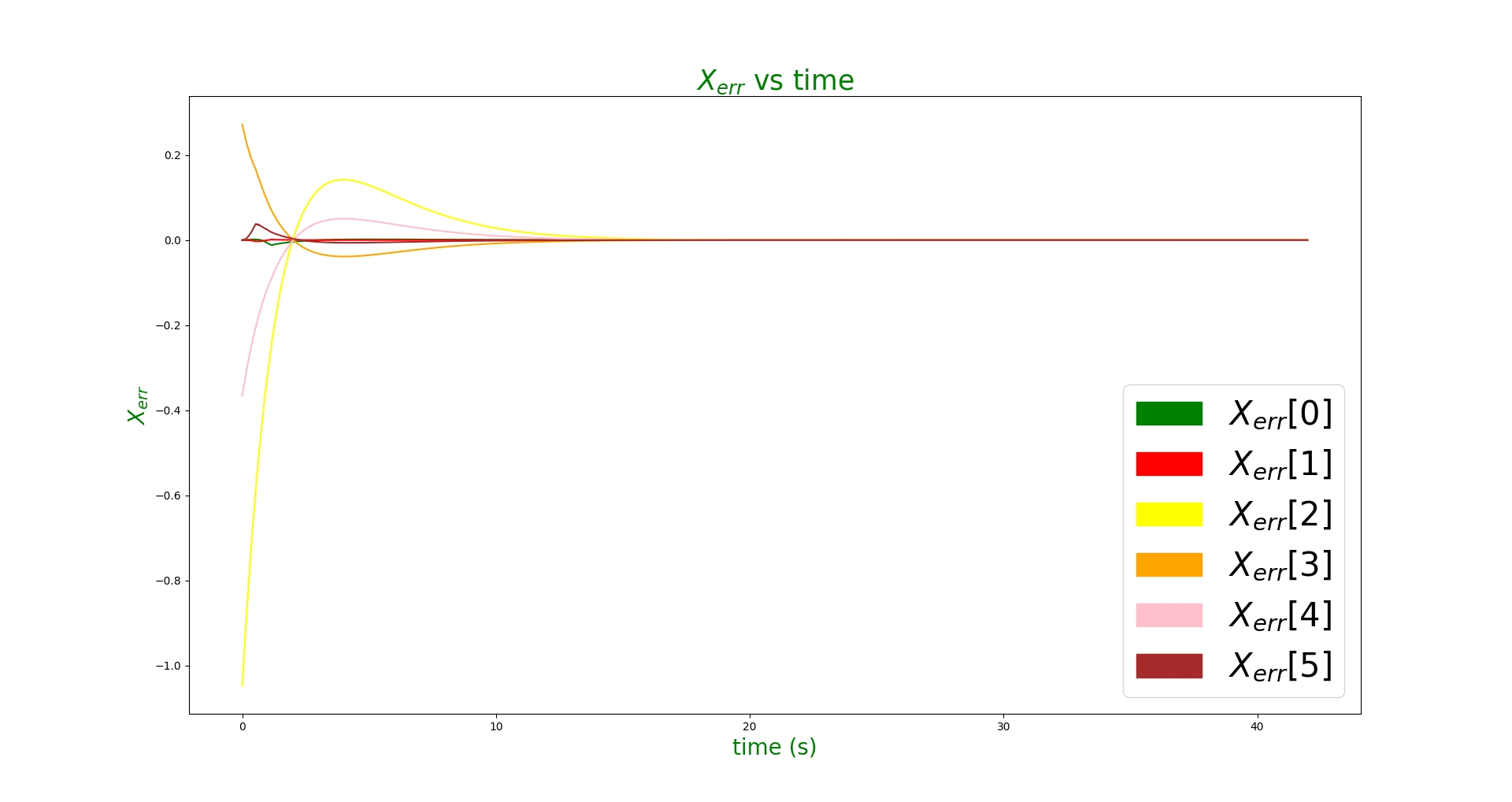
Ki is helpful for tracking problems for achieving absolute and quick convergence to the desired values but they sometimes induce oscillations and overshoots. Hence, this value is kept very low.
Some minor algo details.
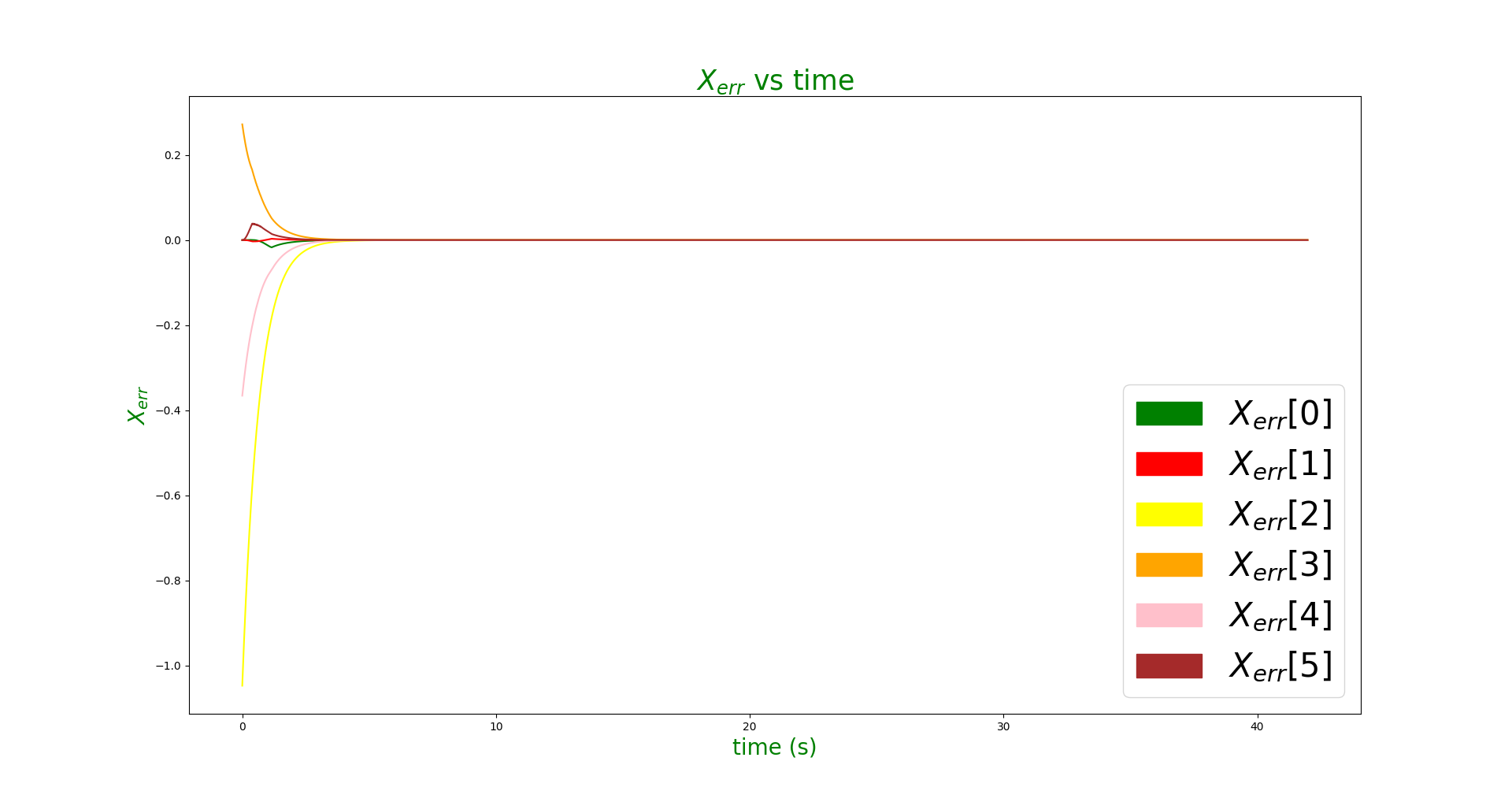
For this problem, I needed to set wheel radius to 1.5 times of the normal wheel radius ( 1.5 * 0.0475 = 0.07125m ) to achieve a satisfactory grasping. A kp value of 1.5 and ki value of 0 was found to give satisfactory results and drove the errors to zero quickly without inducing overshoots.
When the same kp values were tried for the new tasks, the video looked good and the error graph looked almost similar.
If very higher Ki values are used, overshoots were observed and in some cases the error didn't converge to zero before pickup and hence the pikcup failed. When \(K_i\) value of 0.25 and \(K_p\) value of 1.0 was used, the following error pattern and manipulation behavior was observed.
>
Joint Limits
Sometimes the robot involves in self collision like some in the video below.
To avoid this, I also implemented joint limits so that self collisions are avoided. I also implemented singularity checks so that the arm configuration never goes near singulairy. The limits identified for the joints to achieve this objective were as follows
\(\theta_1\) should be between -1.65 to 1.65 ( this limits avoid the arm to go and hit the back of the body or its sides)
\(\theta_2\) should be less than -0.85 (This limit ensures that the arm is stretched out and hence reduces chances of collision)
\(\theta_3\) and \(\theta_4\) are constrained to be less than -0.2 so that the arm doesn’t get close to a singularity.
The robot was able to do good pickup with these limits but I did notice slow convergence of errors and sometimes, very small residual errors remained. This should be because my joint limit values should have been a touch conservative, which explains constant but very small errors. The video showing outputs of joint limits in action is shown below
This video clearly shows that robot avoids self collision using the joint limits yet performs useful pick and place activities.
Due to copyright issues, the code of this project cannot be shared in public. If you like to discuss anything on the implementation, feel free to contact me.
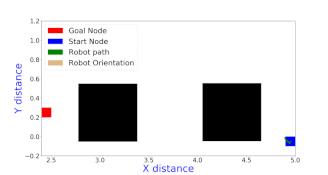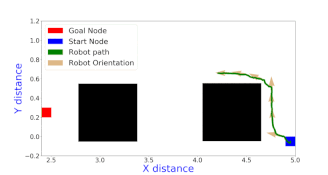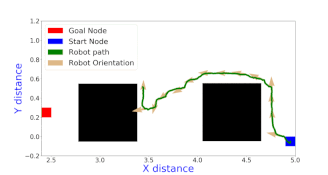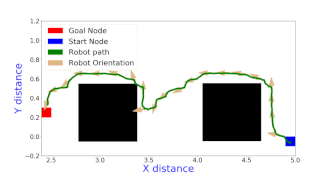
The A star algorithm uses a heuristic along with the node transition cost to evaluate the cost of each neighboring node. All the neighboring nodes of the current node are added to the open list and the node that the robot has currently visited is added to the closed list. In each step of the algorithm, the cheapest node from the open list is picked up and all its neighbors are added to the open list, after ensuring that those neighbors have not been added to the closed list. The termination point of the algorithm is when the goal node is added to the closed list. A star algorithm is both complete and optimal because it will always find a path to the goal (if it exists) and it finds the cheapest path that is available. There were two version of Astar implemented in this work.
Offline version
The term offline indicates that the map for navigation is known before hand. Therefore, a complete path is planned before taking the first step. Then the planned path is executed by using the PID controller. I designed my own heuristic function for this assignment, which calculates the distance between two nodes by splitting the distance into two parts, first a diagonal distance part and then, an axis aligned distance ( horizontal or vertical). The heuristic function that I came up with for this assignment is given below. $$\bar{h}(n) = min({X_{diff}, Y_{diff}}) + | {X_{diff} - Y_{diff}} | $$ where \(X_{diff}\) is the difference in x-coordinates between the goal node and the current node and \(Y_{diff}\) is the difference in y coordinates between the goal node and the current node. The primary intuition behind this heuristic is that it tries to maximize the diagonal distance while trying to calculate the split distance. Since as per the problem description in the assignment, all 8 connected neighbors of a node have uniform costs, this heuristic is the best choice for this problem especially since this heuristic cost equals the true cost in an obstacle free world. The proof of admissibility of this heuristic and more intuition about it is presented in the report.
Online version
The term online indicates that a map is not known before hand and only the nodes that are neighboring to the current node are known and the rest of the map is unexplored. In such scenarios, where backtracking is prohibited or extremely costly, the heuristic designed in the offline version needed modification to make more intelligent decision especially with respect to discriminating multiple nodes which have the same cost as per the offline version heuristic. The heuristic used for this problem is given below $$h_{1}(n) = \sqrt{SLD(g, n) * \bar{h}(n)}$$ where SLD(g, n) stands for the short line distance between the current node and the goal node. In general, I also proposed a family of heuristics defined as given below $$h_k(n) = = \sqrt[k+1]{{\bar{h}(n)}^{k} * SLD(g, n)}$$ With increasing k, the computation time for the heuristic increases but with improved performance. In particular, as k \(\to \infty , h_{k}(n) \to \bar{h}(n)\), which is the true cost in an obstacle free world. The primary intuition behind the formulation of this family of heuristics is that multiplication by SLD brings in a way within the heuristic to prefer nodes which have shorter SLD when their \(\bar{h}(n)\) costs are tied, which turns out to be very useful and taking the k+1 th root just ensures that the heuristic is admissible. More intuition, details, proofs about admissibility are presented in the report.
PID controller
The equation of a PID controller is given below .$$\bar{u}(t) = K_p e(t) + K_I \int_{0}^{t} e(\tau) d\tau + K_D \frac{de(t)}{dt}$$. I implemented a discrete version of PID control for angular velocity.$$\bar{\omega}(t) = K_{wp} e(t) + K_{wi}\sum_{i=0}^{i=t} e(t) \Delta_t + K_{wd} \frac{e(t-1) - e(t)}{\Delta_t}$$. For linear velocity, I just a implemented a proportional controller. $$\bar{v}(t) = K_{vp} * \sqrt{{(\frac{\Delta_x}{\Delta_t})}^{2} + {(\frac{\Delta_y}{\Delta_t})}^{2}}$$
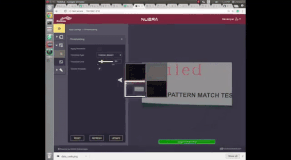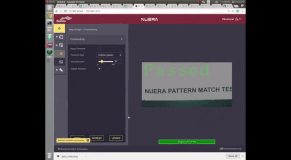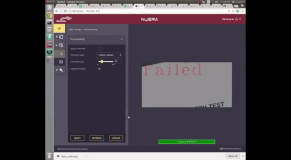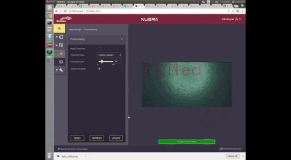
OCV (Optical Character Verification) using smart camera
Brief Description
This project was done as a proof of concept for building a software that verifies if the labels are correctly printed. It should be noted that the verification problem is much simpler version than the recognition problem, where the real question we are asked is to find out what character are present in the given image. But in verification problem, the real question we are being asked is "are these characters same as the characters I showed you previously?". This simplification of verification allows us to construct simple algorithm which do not necessarily understand what characters are present in the image but can verify if the given characters are the same as the characters registered in a template.
Algorithm Description
A template image is first registered. Key points are detected on the template image and descriptors are built for each key point detected. The key point detectors and descriptors used in this work are the ORB feature descriptors. There are more powerful feature descriptors like SIFT but they are not commercial license friendly.
A new query image is given for verification. key points are detected on the query image and key point descriptors are built around each detected key point. Once again, ORB feature descriptors are used in this case
The key point descriptors from query image are matched against key point descriptors from template image and the matching key point pairs are found. Lowe's ratio was used to remove ambiguous matches in this step
Finally, a transformation is computed using the matching key point pairs. This transformation aligns the query image to be in the same pose as the template image. The transformation computed here is the Euclidean transformation since it only involves rotation and translation. But if other variations such as scaling, skew, perspectivity are allowed, one should consider more general transformations, with homography being the top of them all
Finally, after alignment both template image and query image are binarized using otsu's thresholding. Otsu's thresholding is useful in this case since there are only two colors, the foreground and the background. Then difference between the query image and the template image is computed for registered ROI
If the difference image between the two is all zeros, the registered text is present in the given query image and hence, it is declared as a "pass". If the difference image is not all zeros, then it means that the registered text is not present and hence, it is declared as a "Failure"
Sometimes, due to small noises, the difference image will not be all zeros. To avoid this, morphological closing is applied before checking for the difference
If the alignment fails due to lack of key point matches, it also indicates a failure since that can only happen if the template and query image are completely different.
Some tips for speedup
This algorithm took 90 ms on a cortex A9 processor. The main design decision that made this processing time possible were
Choose the right transforms. A homography might be a very tempting choice since its a very general transform that can handle all variations but using a euclidean transform instead of a homography after carefully studying the problem constraints cut 50 ms of processing time
I cut down the pyramid construction in ORB feature generation since scale invariance was not a necessary demand as per problem specification.
Challanges in working with ARM Processors
OpenCv has been around for long and it has been well optimized for Intel chips since the SIMD instruction set for Intel which is SSE is well written for OpenCV, thus exploiting any parallel resources available. But same is not true for ARM chipset. The analogous SIMD instruction for ARM which is NEON is not fully written at the low level for OpenCV, thus missing to exploit available parallel resources. Therefore, if we were to compare the same algorithm running on a quadcore intel and ARM chipset with very similar computing powers, on an average 1:4 slowdown was observed with ARM chipset. At the time of publishing this post (December 2019), there isn't a great effort seen in OpenCV to make it Neon optimised and hence, this slowdown trend is likely to continue for years to come with OpenCV.
The whole algorithm is clearly explained in the video along with a demo
Due to copyrights, I cannot share the code I wrote for my company. Feel free to get in touch with me, if you have doubts in any part of the algorithm.
This project was done as a proof of concept for monitoring if drivers always wear seat belt in lorries. I trained machine learning based object detector for achieving this objective. These algorithms were not coded from scratch. They were coded using OpenCV and SKlean libraries.
Algorithm Description
This is a sliding window detector that classifies each window using a SVM classifier trained on HoG features
To generate training set, 2000 image frames were extracted from a video and each frame was annotated with a Ground Truth bounding box of Seat Belt.
Then a viewing window size was defined and all possible windows were generated by sliding window mechanism. For each window HoG (Histogram of Oriented Gradients) were generated and given a Supervised label of "Seat Belt Detected" or "No Seat Belt Detected". All windows which have at least 90% IoU (Intersection Over Union) with the ground truth bounding box annotation of seat belt were given "Seat Belt Detected" label while others were given "NO Seat Belt Detected" label
After the first set of training, to improve the performance further, hard negative mining was performed (Where many mis-classified were added back to the training dataset)
To improve the quality of the existing data, data augmentation was performed. It must be noted that the type of image augmentations chosen should be thought along with the actual problem in hand. Sometimes, we may end up making the problem more difficult than it actually is by introducing variations that are unlikely to occur in the real use case. This will, in fact bring down the performance from the optimal performance which could have been achieved with carefully chosen variations that fit the problem description
Finally, since we will end up getting multiple detection, I ended up doing Non-Maximum suppression, where multiple local detection are merged into a one peak maxima detection.
The final IoU of the detector turned out to be 75%
. A few more videos showing outputs are shown below.
Card readers are becoming a versatile application in India and this is one such project to read one of India's government Identification cards, which is called the Aadhar. The first idea was to extend this to a lot more Indian government Identification cards like PAN, Passport and Voter Id but we didn't have the time to extend it but this algorithm works well for Aadhar card.
Algorithm Description
The four corners of the card is first found by detecting all the edges of the card using canny edge detection. It must be noted that a clear contrast between the card and its background is assumed for this step. In order to make it more robust, more complex detection algorithms should be used.
A template view of the card is defined based on predefined 2D pose (The card looks absolutely horizontal with no rotation). Now a homography is estimated to align the given card to the predefined 2D pose.
Now the hhomography is applied to transform the card to its template view, where all text is now horizontal. Now, SWT (Stroke Width Transform) is applied to detect all text in the image.
After detecting text, the text is segmented into characters and each character is then recognized using Deep Learning OCR model that we trained. This model was originally trained on 0.1 Million images of handwritten character but this model also offered great performance for printed characters as well
Tesseract Engine can also be used for segmentation and character recognition but many underlying parameters have to carefully fine tuned to get it working to a decent level. But overall, we got better performance with our HCR model on these printed character than the Tesseract Engine on these printed characters. With Tesseract, the accuracy was about 87% while with our custom trained model, the accuracy was about 96%.
This is a project I worked in Soliton, where we deliver R&D as a service. Due to Non-Disclosure Agreements we had with the customer, I cannot reveal any part of the algorithm design. I am just going to state what part I worked in this product, when delivered some parts of this software as a service.
My role in this project
I was a part of the team that developed an algorithm that synthesizes adaptive background for a given album page by picking up colors from all the photos in the page. This was done by Filtering colors according to a definition (which cannot be revealed, because that's propriety of the company)and quantiszed them to pick colors and used them to synthesize a background.
Developed an algorithm for placing decoration objects according to the rules defined by the aesthetics associated with each of them. Came up with a mathematical formulation to measure the aesthetics and storytelling value of a picture.
For more details on the product, visit the product website. This is one of those rare projects, where I am going to state this - " Please don't get in touch with me if you need to know more on this because I cannot reveal more than what I have written here"
RRT is a fundamental planning algortihm in robotics and it is very useful especially when in planning in high dimensional non-convex spaces where discreting the whole space and planning exhaustively based all discrete point is not feasible.
Algorithm Description
A rrt begins by first selecting a sampling a point randomly and cheks if the point is not inside any obstacles
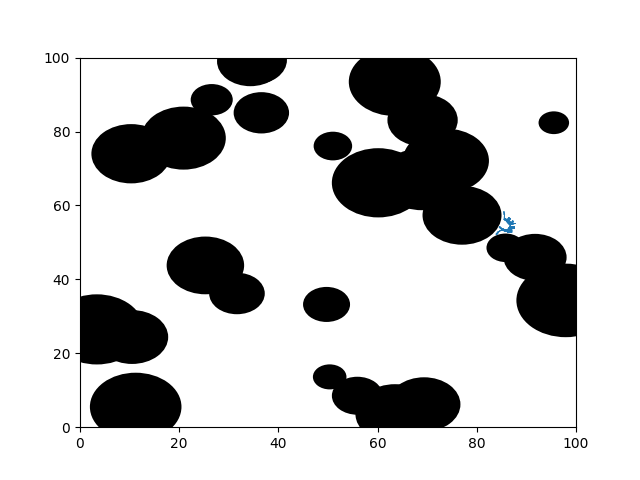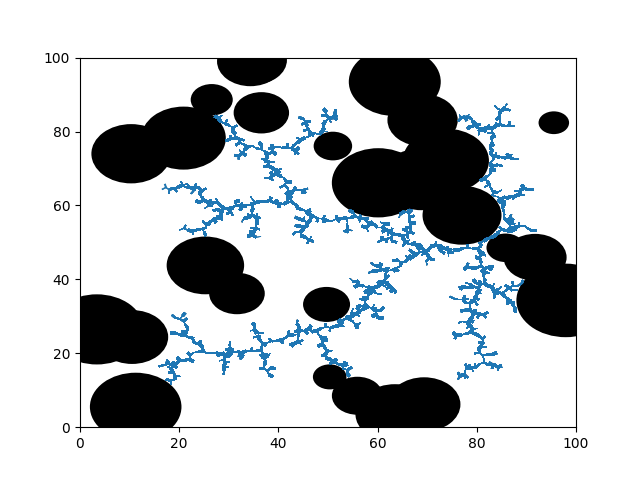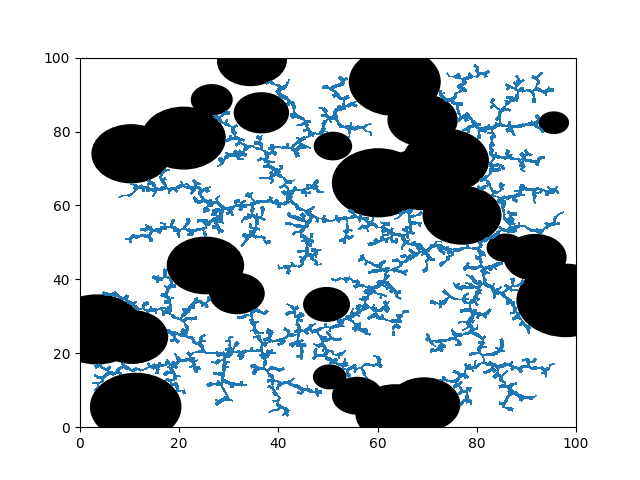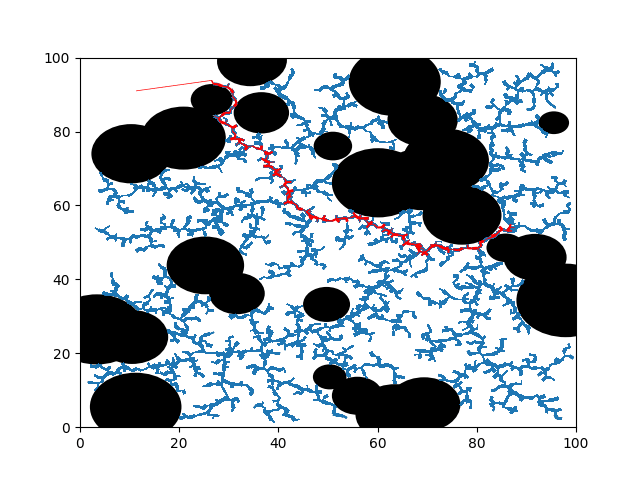
Then the node which is the nearest node to the sampled point is chosen and then a unit vector pointing the direction chosing the sampled point and nearest node on the graph is calculated
Then, the graph is expanded \(\Delta\) distance in the unit vector direction from the nearest node provided the whole extension does not collide with any obstacles. A pesudocode of the whole algorithm is shown below
The termination point of the algorithm is when there is a direct obstacle free path from the one of the nodes in the graph to the goal destination.
A point which needs further eloboration from the above description is how do we check for collision during a node expansion. This checking becomes simplified when all obstacles are circular because all we need to check are only two things
The prependicular distance of the line to be extended from each of the circle center should be less than their respective circle radius
The end points of the line should not line inside any of the circle
Such a simplified implemenation is shown below.
But when we are given random obstacles, we should then use Bresnan's line algorithm to check for collisions all along the line. This is the implementation that is shown at the top of the post.
The code for this implementation can be found at one of my github repos
This project was done during MSR hackathon. The objective was to assemble and control a two Degree of Freedom Pan-tilt mechanism that uses comptuer vision for tracking and following a Blue cube
Detailed Overview
As a first step, I assembled the two servos into a pan-tilt mechanism
Next, after soldering the Pololu Micro-maestro board, I installed its drivers and wrote python wrappers that allowed me to control the pan-tilt servos by specifying a trajectory sequence of angles for both servos
Finally, to achieve the vision based control, I wrote a OpenCV based tracker. Initally, the blue cube is found by masking the blue color and filtering contours based on pre-defined contour properties. Once the cube is detected, it is then tracked using a CSRT tracker through successive frames. The center of the contour defining the blue cube is used for achieving the control. The pixel disparity of the contour center from the image center is calculated in both X and Y direction. The angle of view of the camera was calculated and then the pixel disparity was conveted to proportional angle disparity and this angle was then used a feedback to adjust the pan and tilt servo until the ball was nearly at the center of the image
One complexity that is worth mentioning is the need to invert camera image when the tilt swithces from positive to negative values so that the servo control can be the same at all pan-tilt configurations
There are a lot of short term projects I worked in my previous work experience, for which I cannot showcase the work outside due to the non-disclosure agreement involvement in those works. Nevertheless, I am briefly stating the work experience I had in each of those projects
Deep Learning based projects
In these ages, a computer vision Engineer doesn't exist without knowing deep learning. I worked on a couple of deep learning based porjects
Image Depth Categorisation based on deep learning
Images have to be classified into one of four categories- Close-up, Medium, Long and Ultralong range shot. I generated depth maps for a given image based on pre-trained monocular depth estimation models and constructed a four channel RGBD image by appending the depth map to an RGB image. Then I trained different existing dDeep Learning architectures on 4D images and fine-tuned a model based on ResNet-50 to achieve an accuracy of 85%.
Weed detection and distance estimation using calibrated camera
Trained a weed detection model using tensorflow object detection api. Calibrated the extrinsic parameters of the rover camera with respect to a checker board placed on ground. Found the 3D point that lies at the intersection of ground plane and inverse projection ray (that corresponds to the bottom most pixel of weed). Estimated the distance of the rover to the point using known transformations.
Classical Vision Projects
Shape Context matching as a post-processing to improve Deep Learning HCR accuracy
This is not a real deep learning project but an effort to improve the DL model performance.I improved the accuracy of an AlexNet HCR model from 90.1% to 91.2% by overriding deep learning outputs by shape context-based matching results only for images where the deep learning network was struggling to classify due to very low confidence.In order to achieve this, I had a database of hand written characters to compare against and whenever the deep learning model was not confident enough, I overrode deep learning predictions with Shape context based prediction. To achieve this, I measured the Hausdorff distance between the shape context approximation of the given image and shape context approximation of every image in the database and found the best match (The image with the lowest hausdroff distance with using shape context features.) I Sped up this computation by 3x using parallel processing.
Improving Casting and Bagging Automation system
This is a Jewelry component identification system consisting of 85,000 different Jewellery parts. The existing pipeline that was in action consisted of a size filter(filtering based on contour area), hu moments filter followed by pattern matching.To improve the overall system accuracy, I proposed two changes based on ablative analysis- Using Zernike moments instead of Hu and ORB feature matching instead of pattern matching improved the overall recognition accuracy from 55% to 80%.
Iris recogniton
Developed an end to end iris recognition system involving image acquisition through Soliton smart camera, Iris localization by Daugman’s transform, image normalization and unwrapping, encoding by Gabor wavelets and matching by L2 distance. I didn't really develop any of these algorithms from sratch in this case. I just integrated all the open source code to get a system working.
Tools/ Non-CV project
Dataset Generator
The objective behind this project was to develop a tool that will lower the human effort in data collection. The basic idea was to collect images and auto-tag some of them using on-the-fly machine learning models. Thus this tool runs a weak model automatically on the labeled data collected so far and auto-tags some images within the dataset, which it believes with extreme confidence.
Pin Map Generation
The objective in this project was to find a pin mapping between two devices based on netlist connection given. To do this, I generated a graph representing circuit connections for a given netlist. Then I found the pin mapping between any two terminals present in the circuit by applying shortest path algorithms on the generated graph. This problem setup is challenging particularly because the graph nodes are not simple nodes but electronic components. So electronic circuit knowledge needed to be incorporated to define connectivity between nodes.
I, along with my team in Soliton Conducted three workshops on Computer Vision between 2016-19. I have listed the ppts, link to github repo and the parts I handled for each workshop here. Over the years, I have handled Machine learning and Deep learning in the context of computer vision and fundamentals of projective geometry in these workshops
Anthill Workshop 2018
Anthill is an annual machine learning conference organised in Bangalore. We presented a 2 Day workshop on "DL and ML for computer Vision" at this conference. Link to the workshop
I handled the machine learning part of the workshop.
PSG Workshop 2018
PSG is a reputed college in South India. We were invited to give a two day workshop for the final year undergraduate students and faculty at PSG. Link to the workshop decription
I handled the projective geometry and deep learning part of the workshop.
Anthill Workshop 2017
Anthill is an annual machine learning conference organised in Bangalore. We presented a one Day workshop on "DL and ML for computer Vision" at this conference. Link to the workshop
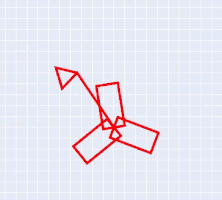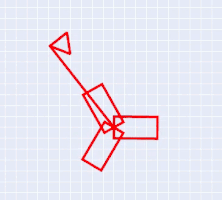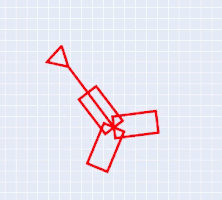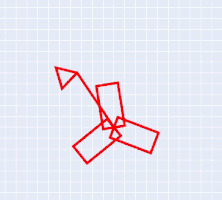
A triangular mass falling in gravity constrained to move in a circular path goes in impact with a rotating windmill.This system consists of two independent rigid bodies.
The rotating windmill is a single DoF body consisting of three rectangular plates joined at the center of one of the edges.
The triangular mass is a 3 DoF system and it is free falling in gravity but it is constrained to move in a circle.
The impact of windmill on the traingular mass is modelled but the impact of triangular mass on the turbine is not modelled. The turbine is modelled to be a very heavy body and triangular mass is much smaller when compared to turbine so that this assumption is meaningful.Therefore, the trainagle doesn't cause any changes through impact to the dynamics of the turbine. But the dynamics of the triangular mass is altered through impacts with the windmill and that is the heart of the project.
Frames setup
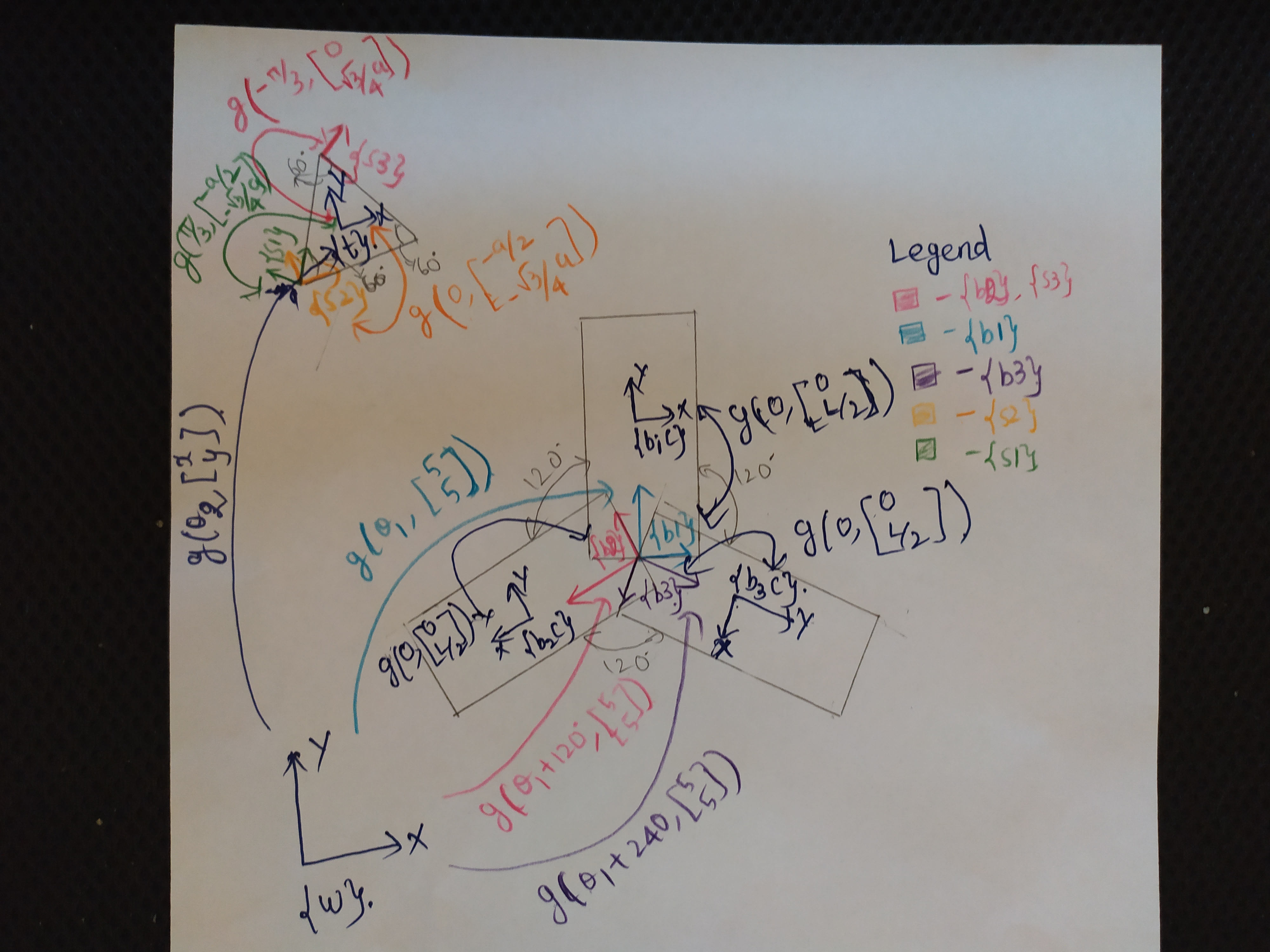
A figure showing all frames used in the project is shown below
Each rectangle in the windmill has a frame and its transformation is given in the figure. The windmill as a whole is a one DoF system and is pivoted at the point X=5, Y=5. The angle between each of the rectangle is 120 degrees. The triangular mass is a 3 DoF system and it has direct transformation characterised by x,y and \(\theta_2\) with respect to the world frame. The triangle is assumed to be equilateral. Not all of these frames are important in lagrangian computation. Some of these frames have been specifically setup for handling impact conditions. Its very easy to define phi conditions for impact if we setup a frame that is aligned with each of the sdies of impact. Frames s1, s2, s3, b1, b2, b3 are used in writing down the equation and limits of impact phi surfaces while b1c, b2c, b3c and t are useful in writing down the lagrangean of the system
Lagrangian setup
The Lagrangrean for the system consits of writing down potential and kinetic energies of the four bodies (three rectangles and one triangle). Gravity is pointing in the negative y direction. So the lagrangian consists of 4 PEs and 4 KEs, one each for each of shapes (3 rectangles and 1 triangle)
Number of degrees of freedom
4 (\(\theta_1, \theta_2, x, y)\)
Constraints
The triangle is contrained to move in a circle. This circle is centered at (5, 13) and has a radius of 5
Impacts
Turbine impacts the triangular mass. In order to achieve this, I had to keep track of 12 edges for the phi surface (9 edges of rectangle + 3 edges of triangle, the pivoted edges of rectangles are ignored because they never involve in impact) and 9 points ( 2 points from each rectangle and 3 points from triangle, the two points on the pivoted edges of the rectangle don't involve in impact). In all I had to check for about 45 impact conditions but I should downplay this exaggeated number by stating that all of them revolve around just 2 or 3 key ideas. The impact update law used is for this work is shown below.
I have used two lambda terms \(\lambda_I\) and \(\lambda_p\) corresponding to two constraints on the generalised moementum after impact in the impact update, because I needed the path constraint for the trianglar mass to be upheld even after impact.
External force / Torque
The windmill is driven by a external torque. This torque is applied to the \(\theta_1\) when solving EL equations of the system.